
教对象Stata系列|第3课:变量管理、统计分析与数据管理
附件:
- 【附件内容】do文件,PDF笔记,录屏
- 【附件下载】链接:https://pan.baidu.com/s/1OX7X6gwd3E1ErQjvibrbUg?pwd=8zbi
本文是教对象Stata系列视频的笔记内容。对应视频与配套代码请见下方链接,笔记内容请见分割线下方。
一、变量管理 (3) : 数值型与字符型变量转换
使用 destring 命令可以将字符型变量转化为数值型变量,使用 tostring 命令可以将数值型变量转化为字符型变量。
1. tostring 命令:数值型 --> 字符型
基础语法:
1 | tostring varlist [, options] |
options:
1 | /* 常用 Options: |
示例:
1 | tostring X, g(Y) // X数值型 --> Y字符型 |
2. destring 命令:字符型 --> 数值型
基础语法:
1 | 字符型 --> 数值型 |
options:
1 | /* 常用 Options: |
示例:
1 | destring X, g(Y) // X字符型 --> Y数值型 |
二、统计分析
1. list 命令:列出变量的取值
使用 list 命令可以按需求列出变量的取值。list 命令可以简写为 l 。
基础语法:
1 | list [varlist] [if] [in] [, options] |
options:
1 | /* 常用 Options: |
示例:
1 | list X if X2==1 // list 配合 IF 条件使用 |
2. summarize 命令:汇报统计量
使用 summarize 可以汇报变量的常见统计量,可简写作 summ 或 su 。
基础语法:
1 | summarize [varlist] [if] [in] [weight] [, options] |
opitons:
1 | /* 常用 Options: |
示例:
1 | summ X1 X2 // X1 与 X2 的样本数、均值、标准差、最大值、最小值 |
3. tabulate 与 tabstat 命令
3.1 tabulate 命令
使用 tabulate 可以查看==某一个数值型/字符型==变量的取值分布与累积百分比情况,简写做 tab 或 ta 。
基础语法:
1 | tabulate varname1 [varname2] [if] [in] [weight] [, options] |
options:
1 | /* 常用 Options: |
示例:
1 | tab X // 查看 X 取值分布 |
3.2 tabstat 命令
与 tab 命令相比,使用 tabstat 命令:
- 可以查看更多统计量
- 可以查看分组统计量
- 仅能查看数值型变量的统计量
基础语法:
1 | tabstat varlist [if] [in] [weight] [, options] |
options:
1 | /* 常用 Options: |
示例:
1 | ** 样本数、均值、最大值、最小值、标准差、极差:根据 Z 变量进行分组,保留两位小数(4f) |
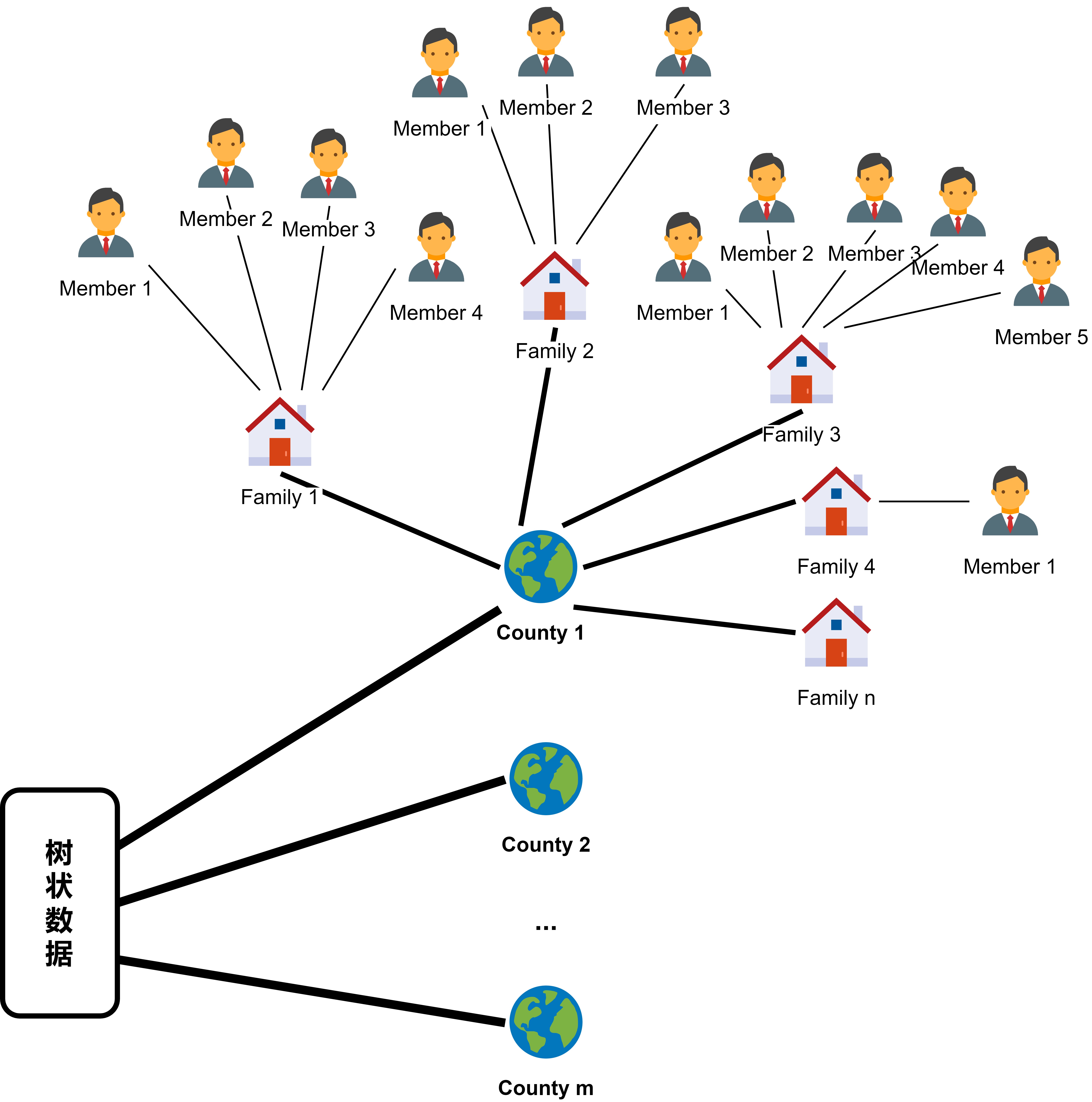
三、关于数据结构
链式数据:严格一对一的对应关系,更常见于多个统计数据库之间
树形数据:存在一对多的对应关系,呈向下分散状,更常见于统计数据内部与抽样调查数据内部
网状数据:可以存在多对多的对应关系,例如一个学生可以选择很多门课程,一个老师也可能教很多门课程
四、数据管理 (1): 数据接驳-append
数据接驳是数据集的纵向扩展,将不同的数据集纵向拼接在一起。
- 数据匹配使用
append命令。与merge不同,数据接驳append命令不需要指定识别变量; - 当前使用的数据是 master data,
append命令可以生成一个结果变量注明样本的来源; - 在接驳的数据集中,变量名相同的变量的值将保存在同一变量名下。
基本语法:
1 | append using filename [filename ...] [, options] |
所有选项 options:
append 的选项大多与 merge 命令相同。
1 | /*Options: |
比较常用的 options 是 keepus(varlist)、gen(newvar) 。
示例:
(⚠️注意:不同设备的显示字体不同,可能会出现字符错位的现象。将错位的文本复制到其他文本编辑器 / Stata do 文件编辑器中,可以解决此问题。)
1 | use "data1.dta" |
五、数据管理 (2): 数据匹配-merge
数据匹配是数据数据的横向合并,目的是添加其他数据库中的某几个变量。使用 merge 命令可以实现数据的精确匹配。
数据匹配是数据集的横向扩展,通过识别某些变量在不同数据集中的对应关系,将其他数据集的一些变量匹配到当前数据中。
- 数据匹配使用
merge命令,当前打开的数据称为 master data,待匹配的数据称为 using data; - 数据匹配包含 1:1,1:m,m:1,m:m 四种类型;
- 在匹配完成后,会生成一个显示匹配结果的变量,默认是“_merge”。
基本语法:
1 | merge X:X varlist using filename [, options] |
所有选项 options:
1 | /*Options: |
merge 命令一般使用 options 较少,比较常用的 options 是 keepus(varlist)、gen(newvar)。
匹配结果:
不论哪种匹配方式,生成的匹配结果变量会有三个固定的取值:
_merge=1:未匹配成功,该样本的数据仅来自 master data;
_merge=2:未匹配成功,该样本的数据仅来自 using data;
_merge=3:匹配成功,该样本的数据同时来自 master data 和 using data;
因此,可以根据匹配结果变量的取值,筛选出需要的样本:
1 | ** 不删除任何样本,直接删除_merge变量 |
1. one-to-one merge
使用 1:1 匹配的条件:用于匹配的 varlist 在 master data 和 using data 中可以唯一识别每一个样本。若某一个变量不能唯一识别每个样本,则要求通过多个变量可以唯一识别两套数据中的每一个样本。
示例:
1 | use "master_data.dta" |
2. one-to-many merge
使用 1:m 匹配的条件:用于匹配的 varlist 在 master data 中可以唯一识别每一个样本,且在 using data 中对应多个样本。
常见使用场景:
- master data 是家庭数据,using data 是个体数据,一个家庭对应多个个体,使用家庭的编码进行识别;
- master data 是省级数据,using data 是地级市数据,一个省对应多个地级市,使用省份的编码进行识别。
示例:
1 | use "master_data.dta" |
3. many-to-one merge
将 1:m 匹配中的 master data 和 using data 的数据特征互换时,就应该使用 m:1 匹配。
使用 m:1 匹配的条件:用于匹配的 varlist 在 using data 中可以唯一识别每一个样本,且在 master data 中对应多个样本。
常见使用场景:
- master data 是个体数据,using data 是家庭数据,多个个体可以同时在一个家庭内,使用家庭的编码进行识别;
- master data 是地级市数据,using data 是省级数据,多个地级市同属于一个省份,使用省份的编码进行识别。
示例:
1 | use "master_data.dta" |
4. many-to-many merge
m:m 匹配不建议使用,因为其匹配结果是不确定的!
在数据匹配时,多数情况使用 1:1、1:m、m:1 已经可以解决问题。此处不再展示 m:m 的用法。
5. 其他数据匹配命令
joinby :解决 merge 的多对多精确匹配问题
reclink :模糊匹配
nearmrg :近似值匹配
mergemany、mergeall:多个文件 (数据库) 匹配
资料来源:
Stata:数据合并与匹配-merge-reclink| 连享会主页 (lianxh.cn)
mergemany -- 一个灵活的命令来合并许多文件 - 简书 (jianshu.com)
mergeall -- 合并多个文件的安全方法 - 简书 (jianshu.com)
6. 数据匹配中常见问题
问 1:能否使用多个变量作为匹配的依据?
答 1:可以,且匹配时应当尽量保证作为匹配依据的变量类型相同:文本对文本,数值对数值
问 2:遇到多对多匹配怎么办?
答 2:不建议使用多对多匹配,绝大多数的多对多精确匹配问题可以通过添加匹配变量解决。例如:在面板数据中加入年份,可以解决某一个体多年编码重复的问题。匹配前应当检查数据是否有误,并充分了解数据结构后再匹配,多数多对多匹配的问题往往来自数据的错误与对数据结构的不了解。
问 3:数据匹配中常见有哪些错误?
答 3:常见错误包括:
_merge变量已存在:多个数据库连续匹配时易出现,删除已有_merge变量,或在匹配时自定义_merge变量的名称- 作为匹配依据的识别变量不能唯一识别所有样本:1) 跨类型数据库、面板数据库匹配时易出现,了解数据库结构后,添加匹配依据变量即可。2) 这类问题还会在数据存在错误时出现,例如作为匹配依据的 ID 生成过程有误,或数据导入数据出错(例如 Excel 导入易出现空白单元格)。
- 变量名重复导致数据被覆盖:using data 仅保留待匹配变量,匹配前核对变量名,是否与master data 重复。
问 4:未匹配成功的样本是否应当保留?
答 4:在不了解数据匹配命令时,不应随意删除样本,大量数据未匹配成功极有可能是数据有误或匹配错了。确认数据无误后,根据研究需要筛选样本,一般仅保留匹配成功的样本,有时也会保留仅来自master data的样本。
 alipay
alipay
