
CMDS数据使用注意事项
中国流动人口动态监测调查数据 (CMDS) 是社会科学领域被广泛使用的公开数据之一,目前公开的数据到2018年。
点击这个链接,可以申请CMDS数据:数据申请 (chinaldrk.org.cn)
然而,一些朋友使用的 CMDS 数据,是从公众号获取、闲鱼等平台购买或者经管之家购买的,使用 CMDS 数据时需要注意以下几点:
- CMDS 不是追踪调查数据,每年的调查数据都是重新抽样的;
- 使用非官方获取的 2018 年数据,可能存在问题
这里重点说第二点问题,即非官方获取的 2018 年数据存在的问题。
1. 数据年份错误
一些非官方获取的 2018 年数据,数据其实是2017年的数据。典型问题是样本总量,2017 年的样本总量是169,899个样本,一些公众号/卖家将2017年数据修改文件名、删除部分变量后,以 2018 年数据的名义售卖。
因此,在使用非官方数据 (特别是2018年) 时,需要特别注意样本量问题。如下图,某公众号宣称的2018年CMDS数据,实际是169899样本的2017年数据(CSV格式的表格,第一行为表头,即变量名)。
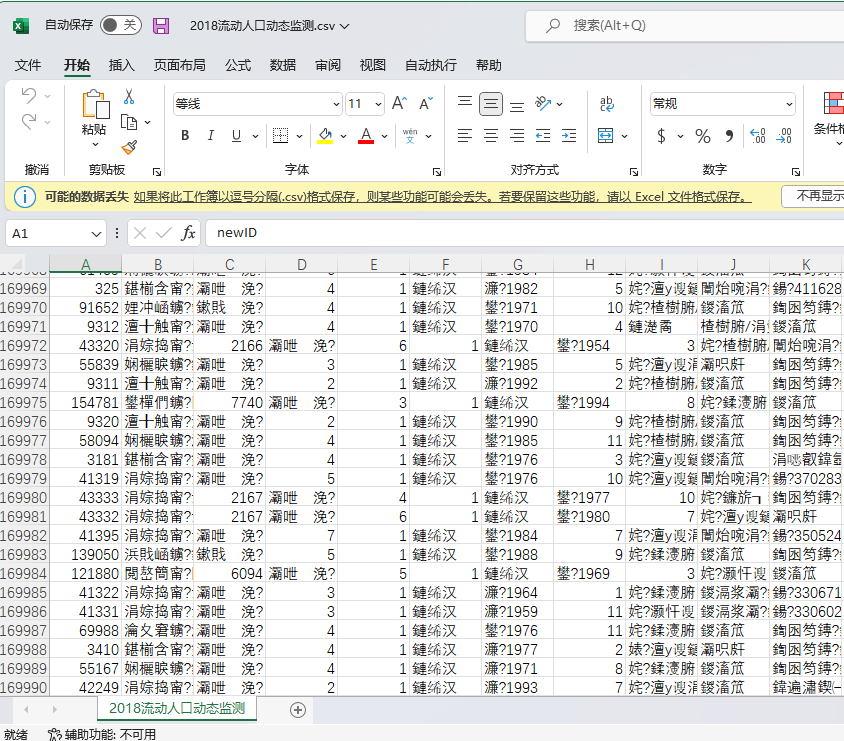
乱码的CSV格式的假数据 (标称2018实为2017)
2. 数据的变量名与问卷不对应
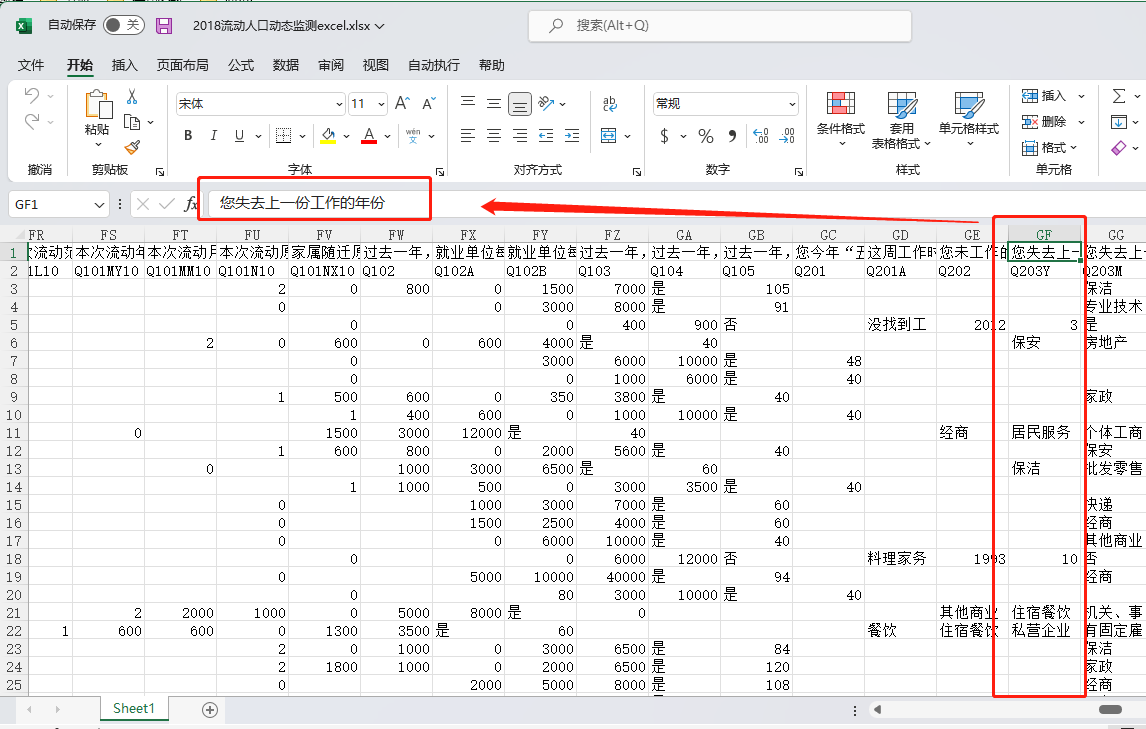
一些非官方获取的 2018 年 Excel 格式 (.xlsx) 的数据,虽然样本量正确,为 152,000 个样本,但是变量名与数据并不对应,且提供的变量名和变量标签是2017年的变量对应表。
考虑到各年调查问卷有所调整,使用该数据无疑会导致使用时出错。因此,需要特别注意变量名与数据的对应关系。
- 样本量正确(为 152,000,与 2017 年的 169,899 有明显区别)
- 错误的数据与变量名的对应关系,例如,GF 列是“您是去上一份工作的年份”,但回答是职业类型与各种数字。

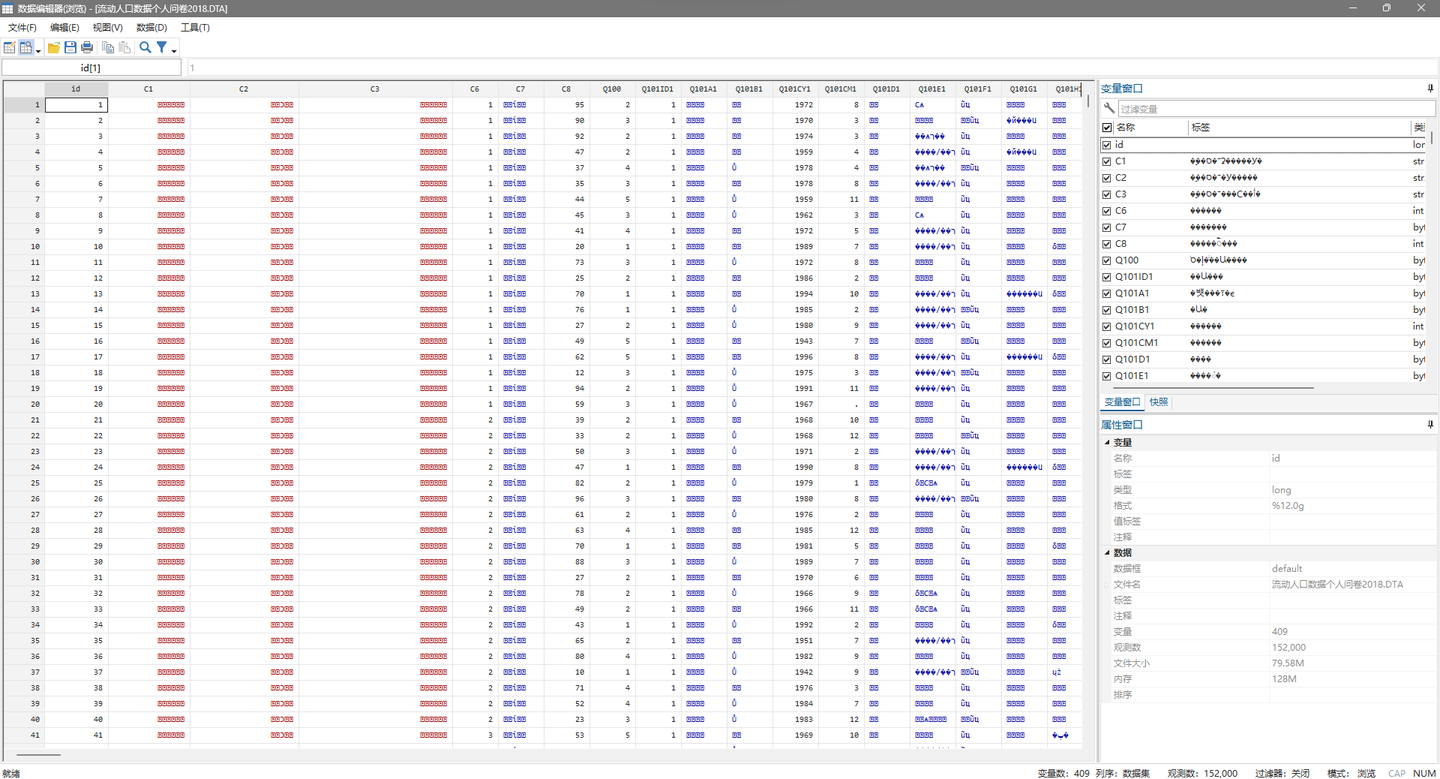
3. Stata 格式数据乱码
官方数据是 152,000 样本的 Stata 格式数据,变量名与数据之间的对应关系正确,但是存在乱码问题。
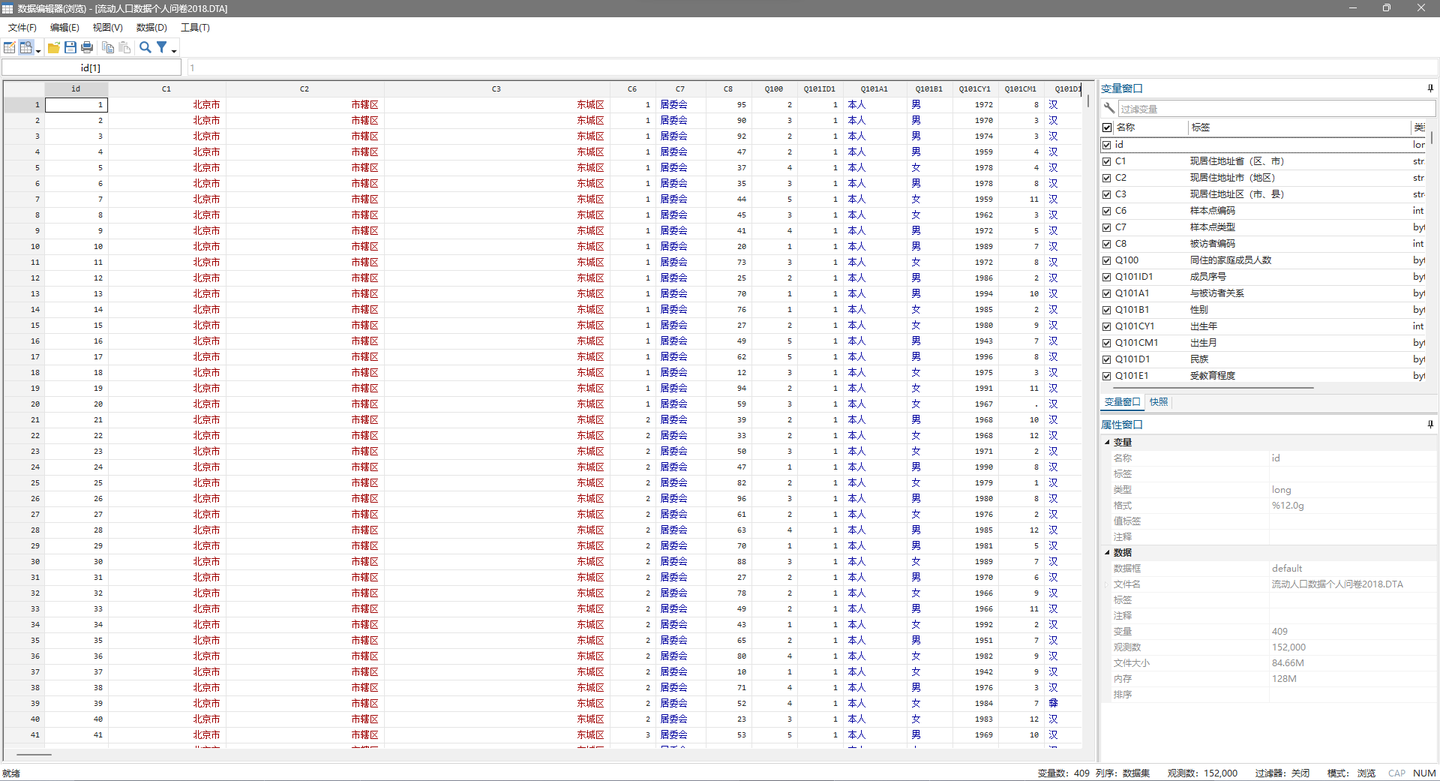
这里可以使用下面命令进行转码。
1 | clear |
转码后即可在 Stata 14 及更新的软件版本中打开,不会存在乱码问题。
总结:
使用网络上购买的公开微观数据库,应当检查以下几点:
- 数据年份是否对应
- 如果数据不是 dta 格式,变量名和数据是否对应
- 数据中存在的其他问题
转载请联系作者,并注明文章来源 https://fgzfgz.github.io
 alipay
alipay
相关推荐

评论