在较新的 Stata 上打开旧版的数据,可能会因中文字符编码问题导致乱码。
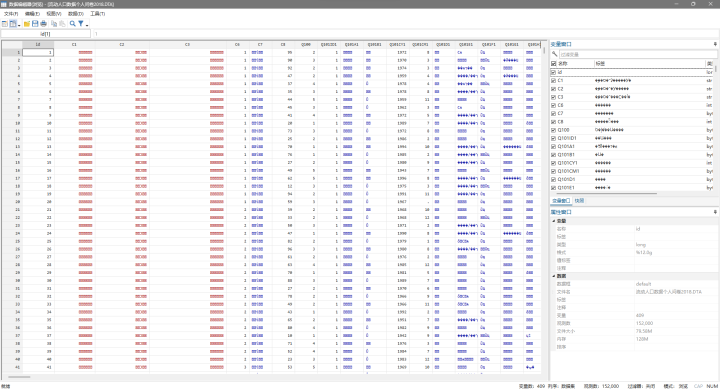
可以将待转码的数据复制到一个转码文件夹中,使用以下命令对数据进行转码:
1
2
3
4
5
6
| ** 解决旧版stata数据中文乱码问题,星号表示通配符
clear
cd "C:\Users\Desktop\转码" // 新建一个转码文件夹,然后修改自己的路径
unicode encoding set gb18030
unicode analyze *
unicode translate *, invalid
|
如果上述操作无法解决乱码问题,可以考虑将通配符改为具体的文件名。
例如:
1
2
3
4
5
| clear
cd "C:\Users\Desktop\转码" // 新建一个转码文件夹,然后修改自己的路径
unicode encoding set gb18030
unicode analyze 流动人口数据个人问卷2018.dta // 文件名根据自己的数据进行调整
unicode translate 流动人口数据个人问卷2018.dta, invalid // 文件名根据自己的数据进行调整
|
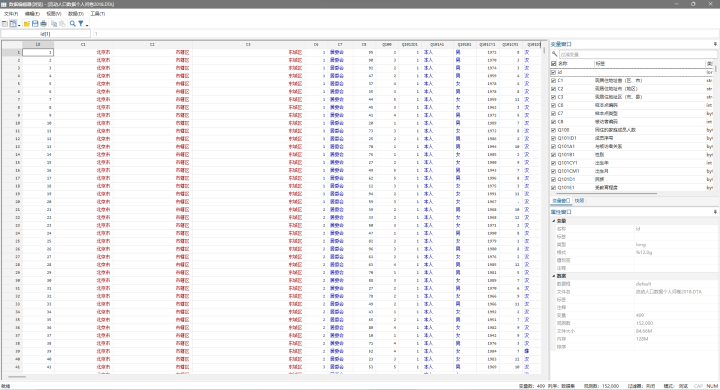
转码后结果如下:
相关链接:
stata 乱码解决方案说明 - 简书 (jianshu.com);Stata15:一次性转码,解决中文乱码问题 - 知乎 (zhihu.com);Stata 中文乱码顽疾解决方法 (360doc.com)
以下数据转码命令来自计量经济圈的分享,不能保证可以解决问题。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
unicode analyze *.do
unicode encoding set gbk
unicode translate *.do
clear
unicode encoding set GB2312
unicode analyze *.dta
unicode encoding set gbk
unicode translate *.dta
cd "C:\Users\hp\Desktop\CFPS_2016_child_dta"
unicode analyze cfps2016child_201709.dta
unicode encoding set gb18030
unicode translate cfps2016child_201709.dta
use "cfps2016child_201709.dta",clear
foreach v of varlist _all {
local type: type `v'
if index("`type'", "str") {
replace `v' = ustrfrom(`v', "gb18030", 1)
}
local lbl: var label `v'
local lbl = ustrfrom("`lbl'", "gb18030", 1)
label var `v' `"`lbl'"'
local newname = ustrfrom(`"`v'"', "gb18030", 1)
rename `v' `newname'
}
cd "C:\Users\hp\Desktop\CLDS\CLDS2012"
unicode analyze CLDS2012househould.dta
unicode encoding set gb18030
unicode translate CLDS2012househould.dta
use "CLDS2012househould.dta",clear
label save using cldslabel.do, replace
|

 alipay
alipay